This month has been packed with releases, dominated by a massive expansion of tools for ComfyUI users alongside powerful new language models and creative suites.
ComfyUI Gets Major Upgrades
Visual and Motion Control
Creators using ComfyUI now have extensive control over their outputs. ComfyUI-Dynamic-Sigmas and ComfyUI-OpenPose-Studio bring visual tuning and pose editing directly to the interface. For animation, ComfyUI-Yedp-Action-Director and ComfyUI-Yedp-Mocap introduce 3D viewports and motion capture capabilities. New nodes like ComfyUI-wan-i2v-control and ComfyUI-Wan-TimeToMove offer precise region and motion guidance for video generation, while ComfyUI_CameraAngleSelector provides an interactive way to choose camera angles.
Workflow Optimization and Management
Managing models is easier with ComfyUI-advanced-model-manager and ComfyUI-Template-Model-Downloader, which automate file organization. Efficiency gets a boost from ComfyUI-CacheDiT and ComfyUI-meancache-z, speeding up generation times. Other handy utilities include ComfyUI-ParallelAnything for multi-GPU processing, ComfyUI Dynamic VRAM for memory optimization, and ComfyUI-IMGNR-Utils for workflow streamlining. Prompt management is covered by ComfyUI-Prompt-Stash and ComfyUI-WildPromptor.
Specialized Generators and Editors
Specific models received dedicated tooling this month. ComfyUI-Flux2Klein-Enhancer and FLUX.2 Klein LoRA Loader refine Flux generation. Video workflows benefit from ComfyUI-PowerLTXLoraLoaderExtra and ComfyUI-ZImageTurboProgressiveLockedUpscale. Image creation is bolstered by Comfy_HunyuanImage3, ComfyUI-ZImagePowerNodes, and the integrated drawing studio ComfyUI-Comfysketch. ComfyUI-Olm-SplineMask allows for precise masking, and ComfyUI-Qwen3-ASR adds speech recognition capabilities.
Language Models for Every Task
High-Performance and Reasoning Models
NVIDIA released gpt-oss-puzzle-88B for efficient H100 deployment, while Nemotron Cascade 2 30B targets local inference. For reasoning, Chuck Norris LLM and GRM2-3b tackle logic and math step-by-step. LongCat-Flash-Prover handles formal mathematics, and MRS-Core provides a reasoning engine for agents. PlaiTO focuses on structured thinking for humanities.
Coding and Multimodal Capabilities
Developers can utilize Qwen3-Coder-Next for coding tasks or run a Character-level GPT transformer to train models from scratch. Multimodal options include MiniCPM-o-4.5 for real-time vision and speech, and Ming-flash-omni-2.0 for unified processing. Qwen3.5-122B-A10B-Uncensored offers uncensored responses, and Nanbeige4.1-3B covers reasoning and code in a compact size. Regency Aghast 27b provides a unique persona-based experience.
Creative Tools for Audio and Video
Video and Image Generation
daVinci-MagiHuman creates audio-video content from text, and SANA-Video generates high-quality 2K videos. Omni-Video 2 combines editing and generation, while ID-LoRA LTX2.3 creates talking-head videos. SAMA-14B allows for instruction-guided video editing. Image tools include Mugen for anime styles, ArcFlow for fast generation, and FreeFuse for combining subjects. Z-Image-Distilled and Z-Image-SDNQ-uint4-svd-r32 offer compressed or faster generation options. Fal Qwen-Image-Edit provides precise camera angle control. SDDj integrates generation into Aseprite. Bytecut Director organizes production workflows, and AI Video Clipper LoRA helps prepare training data.
Audio and Speech Synthesis
Music generation sees a huge upgrade with ACE-Step 1.5, which generates full songs locally in seconds. MOSS-TTS Family and MioTTS Inference offer high-fidelity speech options. PrismAudio generates audio from video using planning, and Speech Swift brings speech tools to Apple Silicon. Voice Clone Studio and WAVe-1B-Multimodal-NL provide comprehensive audio editing and quality checking tools.
Developer Utilities and Datasets
Hardware and infrastructure tools are essential this month. UniInfer checks model compatibility before download, while Strix Halo AI Stack turns AMD machines into AI servers. Lemonade offers a unified local server, and Lora Pilot bundles training tools into Docker. AI Toolkit now supports LTX 2.3 training. Kreuzberg v4.5.0 extracts text from documents, and GLM-OCR reads complex files. For datasets, CaptionFoundry and ImageTagger assist with annotation, alongside SyntheticGen for remote sensing data. Google Code Archive and The Michael Hafftka Catalog preserve code and art history, while WorldVQA tests visual knowledge. SD Webui Style Organizer and OmniPromptStyle CheatSheet help users manage prompts and styles. The llama.cpp MCP Client was also updated for tool use.

Visualize and Control Noise with ComfyUI-Dynamic-Sigmas Tool
31 March 2026
ComfyUI-Dynamic-Sigmas is a custom node for ComfyUI that gives users visual control over sigma schedules during the diffusion process. It allows both beginners and advanced users to create, tune, and […]

daVinci-MagiHuman Conjures Expressive Talking Videos from Text
31 March 2026
daVinci-MagiHuman is an open-source audio-video generation model that creates synchronized video and audio content from text prompts. The model uses a single-stream Transformer architecture to process text, video, and audio […]

NJToolsDev Automates Setup with ComfyUI-Template-Model-Downloader
31 March 2026
ComfyUI-Template-Model-Downloader is a Python script that automatically downloads all model files required by ComfyUI's official built-in workflow templates. It places each file into the correct subfolder under the ComfyUI models […]

NVIDIA Unlocks Speed with New gpt-oss-puzzle-88B Model
31 March 2026
NVIDIA has released gpt-oss-puzzle-88B, a large language model built for efficient deployment on H100-class hardware. The model uses a Mixture-of-Experts architecture with 88 billion parameters and is designed to handle […]

Mugen by Cabal Research Elevates Anime Character Creation
31 March 2026
Mugen is a new AI image model that converts SDXL architecture to Flux 2 VAE, designed specifically for anime-style generation. It represents a significant departure from the original NoobAI models […]

SDDj supercharges Aseprite with offline AI animation
30 March 2026
SDDj is a local image generation and animation extension for Aseprite that combines Stable Diffusion with AnimateDiff. It runs entirely on your computer, generating images and animations directly within the […]

Andreszs Debuts ComfyUI-OpenPose-Studio for Visual Pose Editing
30 March 2026
ComfyUI-OpenPose-Studio is a new extension that brings visual pose editing directly into the ComfyUI interface. Users can create, adjust, and organize OpenPose skeletons without leaving their workflow, making it easier […]

UniInfer Checks Hardware Fit Before You Download AI Models
30 March 2026
UniInfer is an open-source inference runtime that checks if an AI model fits your hardware before you download it. It calculates VRAM requirements and overhead to prevent out-of-memory errors before […]

Olli Sorjonen Debuts ComfyUI-Olm-SplineMask for Precise Image Masks
30 March 2026
ComfyUI-Olm-SplineMask is a custom node for ComfyUI that enables users to draw precise masks using spline shapes. Instead of painting masks with a brush, users define areas by placing points […]

Vavo Debuts LoRA Pilot for Hassle-Free AI Model Training
30 March 2026
Lora Pilot is an all-in-one Docker workspace that bundles Stable Diffusion LoRA training tools into a single container. It combines dataset preparation, model management, training, and inference workflows so users […]

Kreuzberg v4.5.0 supercharges AI pipelines with layout detection
30 March 2026
Kreuzberg v4.5.0 is a document intelligence framework that extracts text, structure, and metadata from over 88 file formats. Written in Rust, it provides native bindings for 12 programming languages including […]

Dealignai unleashes Nemotron Cascade 2 30B A3B UNCENSORED JANG 2L
30 March 2026
Nemotron Cascade 2 30B A3B UNCENSORED JANG 2L OR is a new large language model release designed for efficient local inference. The model uses a unique Cascade architecture with 30 […]

Qwen3.5 122B A10B Uncensored HauhauCS Aggressive Defies Limits
30 March 2026
Qwen3.5-122B-A10B-Uncensored-HauhauCS-Aggressive is a large language model modified to remove all refusal responses while keeping its original capabilities intact. The release achieves zero refusals across 465 tested prompts without any degradation […]

Eamon2009 Brings Transformer Language Model Training to Home PCs
30 March 2026
A new character-level GPT transformer built in PyTorch lets users train language models from scratch without any pre-trained weights or cloud computing. The project generates story-like text by learning character […]

Meituan Debuts LongCat-Flash-Prover for Formal Math Proofs
30 March 2026
LongCat-Flash-Prover is a 560-billion-parameter open-source model designed to handle formal mathematical reasoning. It uses a Mixture-of-Experts architecture to perform tasks like writing formal proofs, translating informal math problems into formal […]

Strix Halo AI Stack Transforms AMD PCs Into AI Servers
30 March 2026
Strix Halo AI Stack is an Ansible playbook that transforms AMD Strix Halo machines into local AI inference servers with a single command. The tool automates the entire setup process, […]

SyntheticGen Crafts Balanced Data for Smarter Satellite AI
30 March 2026
SyntheticGen is a new open-source tool that creates synthetic training data for remote sensing segmentation tasks. It allows users to generate images with explicit control over class distributions, addressing the […]

Comfy Team Revolutionizes AI Memory with ComfyUI Dynamic VRAM
30 March 2026
ComfyUI Dynamic VRAM is a new memory optimization system designed to help users run large AI models on hardware with limited memory. It introduces a custom PyTorch VRAM allocator that […]

PrismAudio Transforms Video into Realistic Soundtracks
30 March 2026
PrismAudio is a new framework that generates audio from video using reinforcement learning with Chain-of-Thought (CoT) planning. Developed by the FunAudioLLM team, it breaks down the complex task of video-to-audio […]

Never Lose an Idea with ComfyUI-Prompt-Stash by Phazei
30 March 2026
ComfyUI-Prompt-Stash is a custom node plugin for ComfyUI that allows users to save, organize, and manage text prompts directly within their workflow. The tool creates a centralized prompt library that […]

Phazei Debuts ComfyUI-PowerLTXLoraLoaderExtra for LTX2 Control
30 March 2026
ComfyUI-PowerLTXLoraLoaderExtra is a custom node for ComfyUI that gives users precise control over multiple LoRAs in LTX2 video generation workflows. The tool provides layer-specific strength adjustments for different aspects of […]

Master FLUX Edits with ComfyUI-Flux2Klein-Enhancer Toolkit
30 March 2026
ComfyUI-Flux2Klein-Enhancer is a custom node pack for ComfyUI that gives users precise control over FLUX.2 Klein image generation and editing. It manipulates text conditioning and reference latents to adjust how […]

nauno40 Drops OmniPromptStyle CheatSheet for AI Model Comparison
30 March 2026
OmniPromptStyle CheatSheet is a visual, searchable database that helps users compare how different AI image models respond to the same artistic prompts. The tool supports Stable Diffusion 1.5, SDXL, and […]

Train Lightricks Videos Locally with New LTX 2.3 Support
30 March 2026
AI Toolkit now includes LTX 2.3 support for fine-tuning the video generation model from Lightricks. A recent merge adds training capabilities for the latest version of this model, allowing users […]

ComfyUI Node Organizer Update Rewrites Workflow Management
30 March 2026
ComfyUI Node Organizer version 2 is a complete rewrite of the previous Node Organizer tool by the same developer. It automatically arranges nodes in ComfyUI workflows, keeping groups compact and […]

SD Webui Style Organizer transforms style selection with visual grid
30 March 2026
SD Webui Style Organizer is an extension that replaces the default style dropdown in Stable Diffusion WebUI with a visual grid interface. Users can browse, select, and apply styles through […]

FPHam Channels Jane Austen in Regency Aghast 27b Update
26 March 2026
Regency Aghast 27b is a large language model designed to function as a specific persona from a bygone era. It operates under the belief that it is an artificial intelligence […]

OpenBMB Debuts MiniCPM-o-4_5: Real-Time Vision and Voice AI
26 March 2026
MiniCPM-o-4.5 is a multimodal AI model that processes vision, speech, and live streaming inputs in real-time. Developed by OpenBMB, this 9-billion parameter model can see, listen, and speak simultaneously through […]

Yuriyvnv Refines Dutch Speech Data With WAVe Update
26 March 2026
WAVe-1B-Multimodal-NL is a 1 billion parameter model that checks the quality of synthetic speech at the word level. It examines how well spoken audio matches its written transcript, catching errors […]

Chuck Norris LLM Flexes Reasoning Muscles
26 March 2026
Chuck Norris LLM is a 32-billion parameter language model fine-tuned from Qwen3 with chain-of-thought reasoning capabilities. The model tackles math, logic, and coding tasks while showing its work step-by-step, making […]

Speech Swift Delivers Voice AI for Apple Silicon
26 March 2026
Speech Swift is a comprehensive AI speech toolkit designed specifically for Apple Silicon devices. It allows users to run powerful speech models locally, including tools for speech recognition, text-to-speech synthesis, […]

OrionLLM GRM2 Packs Giant Reasoning Power in Small Model
26 March 2026
GRM2-3b is a new 3-billion parameter AI model built for long-term reasoning and complex problem-solving. Despite its small size, it competes with much larger models in benchmarks and handles multi-step […]

ID-LoRA LTX2.3 Creates Talking Heads with Synced Audio
26 March 2026
ID-LoRA LTX2.3 is a new tool that generates talking-head videos with synchronized audio using a reference voice and image. It creates personalized video content where both the visual appearance and […]
SAMA-14B Masters Video Editing While Preserving Motion
26 March 2026
SAMA-14B is a new open-source AI model designed for instruction-guided video editing. It allows users to modify videos using text instructions while keeping the original motion and temporal details intact. […]

ComfyUI FLUX.2 Klein LoRA Loader Ends LoRA Guesswork Today
26 March 2026
A new ComfyUI custom node called FLUX.2 Klein LoRA Loader brings architecture-aware loading to the FLUX.2 Klein 9B model. The tool automatically converts diffusers-format LoRAs to native FLUX format while […]

Seamless model browsing with ComfyUI-advanced-model-manager
26 March 2026
ComfyUI-advanced-model-manager is a custom node that brings model browsing and downloading directly into ComfyUI. Users can search across hundreds of HuggingFace repositories, download files to the correct folders, and manage […]

ImageTagger Debuts to Clean Machine Learning Datasets
26 March 2026
ImageTagger is a desktop annotation tool designed for managing image and text pairs, specifically built for machine learning dataset curation workflows. The application provides a streamlined interface for teams and […]

Michael Hafftka Catalog Raisonné Chronicles 50 Years of Art
26 March 2026
The Michael Hafftka Catalog Raisonné is a new open dataset containing approximately 3,800 artworks by a single artist spanning five decades. The collection covers work from the 1970s through 2025 […]

NVIDIA SANA-Video Accelerates 2K AI Video Creation
26 March 2026
SANA-Video is a new diffusion model designed to create high-quality videos from text prompts. It can generate content up to 2K resolution with minute-long duration while maintaining strong alignment between […]

Nanbeige4.1-3B Bridges Reasoning and Agents in a Compact Model
22 March 2026
Nanbeige4.1-3B is a compact 3-billion parameter language model designed to handle reasoning, code generation, and agentic tasks in one package. The model performs multi-step problem solving while maintaining alignment with […]

OpenMOSS MOSS-TTS Speech Studio for home GPUs
22 March 2026
MOSS-TTS Family is an open-source speech and sound generation model family from MOSI.AI and the OpenMOSS team. It is designed for high-fidelity audio generation across complex real-world scenarios, including long-form […]

Aratako Brings MioTTS Inference for Fast Local Voice Cloning
22 March 2026
MioTTS Inference is a text-to-speech system that uses large language models to generate natural-sounding speech. The project offers multiple model sizes ranging from 0.1B to 2.6B parameters, allowing users to […]

llama.cpp MCP Client Gives Your Local AI Real World Skills
21 March 2026
A new update to llama.cpp introduces an MCP Client that brings tool use and agentic capabilities to local AI workflows. This client connects llama.cpp to external tools and data sources […]

Bytecut Director by Heheok Streamlines AI Video Production
21 March 2026
Bytecut Director is a new open-source production workspace designed to organize and streamline AI video generation workflows. It functions as a bridge between the creative planning process and the technical […]

1038lab Unveils ComfyUI-WildPromptor for Easy Prompts
21 March 2026
ComfyUI-WildPromptor is a custom node extension for ComfyUI that streamlines prompt creation and management through a visual dropdown interface. Instead of memorizing wildcard names, users can browse and select keywords […]

Draw Inside ComfyUI with ComfyUI-Comfysketch Node
21 March 2026
ComfyUI-Comfysketch is a new custom node that integrates a comprehensive drawing studio directly into the ComfyUI interface. It allows users to create and edit sketches with layers and multiple brush […]

EricRollei Brings To Comfy_HunyuanImage3 Hunyuan Image 3.0
21 March 2026
Comfy_HunyuanImage3 is a set of ComfyUI custom nodes for a collection of quantized versions of the HunyuanImage-3.0 image model. The integration provides professional tools for text-to-image generation, image editing, and […]

ArcFlow Generates AI Images in Just Two Steps
20 March 2026
ArcFlow is a new framework that generates images from text prompts in just two processing steps. It achieves this by using curved mathematical paths instead of straight shortcuts, which better […]

Fudan-FUXI Unveils Omni-Video 2 AI Tool
20 March 2026
Omni-Video 2 is a unified video editing and generation framework that combines a text-to-video diffusion model with vision-language understanding. The system can generate videos from text descriptions and edit existing […]

FranckyB Updates Voice Clone Studio App
18 March 2026
Voice Clone Studio is a modular Gradio-based web application that handles voice cloning, voice design, multi-speaker conversations, voice conversion, and sound effects generation. The tool consolidates multiple AI audio engines […]

New ComfyUI-ZImageTurboProgressiveLockedUpscale
18 March 2026
ComfyUI-ZImageTurboProgressiveLockedUpscale is a new custom node for ComfyUI that handles progressive image upscaling through multiple stages. The node takes a different approach than traditional methods by using sigma slicing and […]

Generate Various ControlNets with ComfyUI-Yedp-Action-Director
18 March 2026
ComfyUI-Yedp-Action-Director is a custom node that has a fully interactive 3D viewport directly into ComfyUI. Users can load 3D character animations from .FBX, .GLB, or .BVH files, preview them in […]

Speed Up Z-Image with ComfyUI-meancache-z by Facok
17 March 2026
ComfyUI-meancache-z is a new custom node that accelerates inference for Z-Image Flow Matching models without requiring any model fine-tuning. The tool, similar to the Z-Image loras, achieves speedups between 1.4x […]

InclusionAI brings Any to Any with Ming-flash-omni-2.0 LLM
17 March 2026
Ming-flash-omni-2.0 is a unified multimodal model from inclusionAI that processes images, text, audio, and video while generating both speech and images. Built on a Mixture-of-Experts (MoE) architecture with 6 billion […]

MRS-core A Reasoning Engine for AI Agents
17 March 2026
MRS-Core is a deterministic reasoning engine built for large language models and autonomous agents. It provides a modular foundation constructed from a small set of reusable operators that execute in […]
MoonshotAI WorldVQA Tests AI Memory
17 March 2026
WorldVQA is a new benchmark designed to test how well AI models can identify and name visual objects from memory. Created by MoonshotAI, it measures factual visual knowledge rather than […]

Shootthesound controls Wan 2.2 with ComfyUI-wan-i2v-control
17 March 2026
ComfyUI-wan-i2v-control is a custom node pack for ComfyUI that brings precise region control to WAN image-to-video generation. The tool intercepts the conditioning process and applies masks to specific areas, letting […]

ImagineerNL Releases ComfyUI-IMGNR-Utils Nodes
17 March 2026
ComfyUI-IMGNR-Utils is a quality-of-life node pack that streamlines workflows in ComfyUI. It reduces unnecessary clicking and helps keep your workspace organized by addressing common annoyances users face when building AI […]
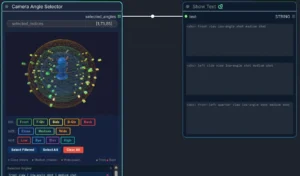
NickPittas 3D ComfyUI_CameraAngleSelector Node
17 March 2026
ComfyUI_CameraAngleSelector is a custom node for ComfyUI that provides an interactive 3D interface for selecting camera angles. It allows users to visually choose from 96 different camera angle combinations rather […]

New 96 Angles Qwen-Image-Edit-2511-Multiple-Angles-LoRA
17 March 2026
Fal has released Qwen-Image-Edit-2511-Multiple-Angles-LoRA, a new tool designed to give users precise control over camera angles during the image editing process. This Low-Rank Adaptation (LoRA) allows for the selection of […]

FearL0rd ComfyUI-ParallelAnything Tool for 2 or more GPUs
17 March 2026
ComfyUI-ParallelAnything is a custom node suite for ComfyUI that enables true parallel processing across multiple GPUs. Unlike standard offloading methods that move a single model between devices, this tool creates […]

ACE-Step 1.5 ComfyUI Generates Songs Locally
17 March 2026
ACE-Step 1.5 ComfyUI brings commercial-grade music generation to local machines. This open-source audio model now runs natively in ComfyUI and can create full songs in under 10 seconds using standard […]

Cyberbol Released AI Video Clipper LoRA Tool For Caption Generation
17 March 2026
AI Video Clipper LoRA is a dataset preparation tool that helps users create training data for video LoRA models such as LTX-2 and HunyuanVideo. The software automatically processes long videos, […]

Z-Image-Distilled Speeds up Z-Image in only 10 Steps
17 March 2026
Z-Image-Distilled is a new image generation model that speeds up the creation process while keeping the original Z-Image style intact. It produces quality images in just 10 to 20 steps, […]

ComfyUI-Yedp-Mocap mocap that Saves VRAM
16 March 2026
ComfyUI-Yedp-Mocap is a new custom node suite for ComfyUI that performs motion capture directly in your web browser. It handles the detection of poses, hands, and faces by utilizing the […]

ComfyUI-CacheDiT Speed Boosts DiT models
16 March 2026
ComfyUI-CacheDiT is a new custom node that accelerates Diffusion Transformer (DiT) models in ComfyUI. It delivers 1.4 up to 2 times faster generation speeds through intelligent caching, with no manual […]

FreeFuse LoRA framework for AI Art
15 March 2026
FreeFuse is a new framework that allows users to combine multiple specific subjects into a single AI-generated image without retraining models. It uses a method called Adaptive Token-Level Routing to […]

Alibaba-pai Z-Image-Fun-Lora-Distill for Fast Images
15 March 2026
Z-Image-Fun-Lora-Distill is a new LoRA adapter that speeds up image generation for the Z-Image model. It reduces the number of inference steps required while also handling CFG internally, making the […]

ACE-Step Pumps It Up With Ace-Step 1.5
15 March 2026
ACE-Step 1.5 is a new open-source music generation model that brings commercial-grade audio creation to consumer hardware. It generates full songs in under 10 seconds on an RTX 3090 while […]

Nyuuzyou Preserves Google Code Archive
15 March 2026
The Google Code Archive is a massive dataset that preserves source code from the defunct Google Code hosting service. It contains over 65 million files gathered from nearly 500,000 repositories, […]

Z.ai Team Gets Efficient with GLM-OCR
15 March 2026
GLM-OCR is a new open-source model designed to read and understand complex documents. It uses a compact architecture to pull text, formulas, and tables from images and PDFs. The tool […]

Alibidaran debuts PlaiTO for reasoning
15 March 2026
PlaiTO is a reasoning-focused language model built on LLaMA 3.1 (8B) that emphasizes structured thinking over basic text generation. The model targets humanities and social sciences, specifically handling abstract concepts […]

Unsloth Provides GGUFs for Qwen3-Coder-Next
15 March 2026
Qwen3-Coder-Next is an open-weight language model built specifically for coding agents and local development workflows. The model uses a mixture-of-experts (MoE) architecture with 80 billion total parameters, but cleverly only […]

Quantization for Z-Image-SDNQ-uint4-svd-r32
12 March 2026
Z-Image-SDNQ-uint4-svd-r32 is a compressed version of the Tongyi-MAI/Z-Image text-to-image model that uses 4-bit quantization to significantly reduce file size. The model generates images from text prompts while maintaining most of […]

Lemonade-sdk adds image support to lemonade
12 March 2026
Lemonade is an open-source local AI server that lets users run LLMs, and speech tools directly on their own hardware. The project provides a unified API that combines text, audio […]
DarioFT Releases ComfyUI-Qwen3-ASR for Qwen3-ASR
2 March 2026
ComfyUI-Qwen3-ASR is a new custom node pack that brings automatic speech recognition to ComfyUI. It transcribes audio files into text across 52 different languages and dialects, making it a useful […]
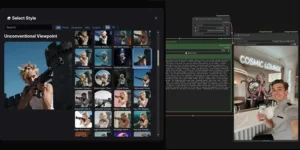
More Z-Image nodes ComfyUI-ZImagePowerNodes
2 March 2026
ComfyUI-ZImagePowerNodes is a new collection of custom nodes designed specifically for the Z-Image Turbo model in ComfyUI. The package centers around the ZSampler Turbo, a specialized sampler that produces high-quality […]
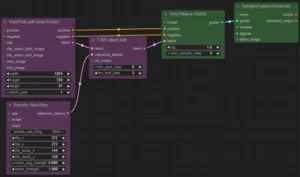
GiusTex Unveils ComfyUI-Wan-TimeToMove Node
2 March 2026
ComfyUI-Wan-TimeToMove is a new custom node package that brings Time-to-Move motion control to ComfyUI. It allows users to guide video generation with specific motion signals, giving creators control over how […]
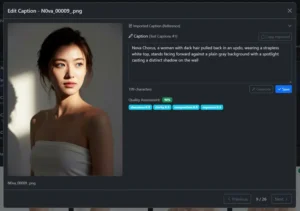
CaptionFoundry Free Captioning Tool
1 March 2026
CaptionFoundry is a free desktop application that helps users prepare image datasets for AI model training. It uses local vision AI models to automatically generate captions for images, eliminating the […]








