









DC-VideoGen: 14.8x Faster Video AI
# DC-VideoGen: Revolutionizing Video Generation Efficiency
Breakthrough in Video AI Performance
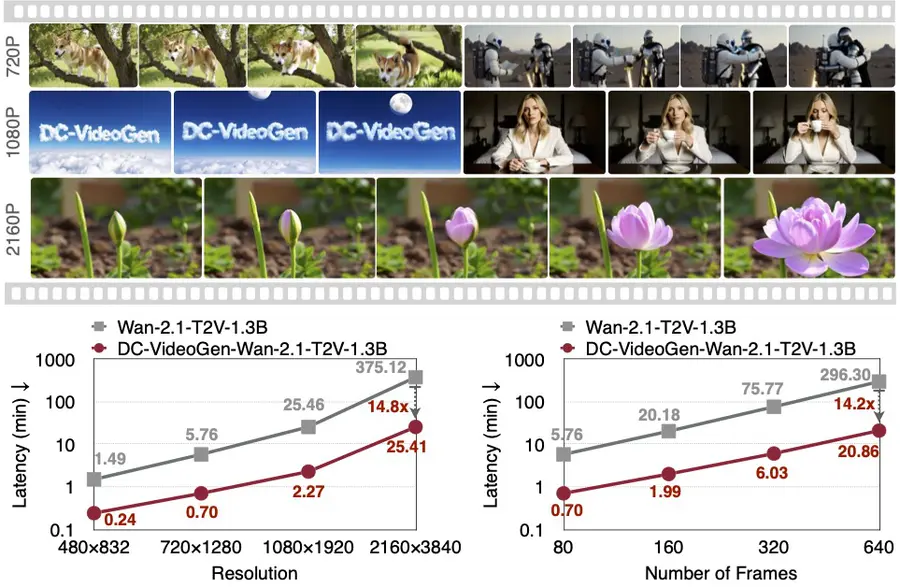
MIT Han Lab has introduced DC-VideoGen, a groundbreaking post-training framework designed to dramatically accelerate video diffusion models. The project delivers remarkable performance improvements, enabling video generation up to 2160×3840 resolution on a single NVIDIA H100 GPU with unprecedented efficiency.
Core Technical Innovations
DC-VideoGen builds on two critical innovations:
- Deep Compression Video Autoencoder (DC-AE-V) providing 32×/64× spatial and 4× temporal compression
- AE-Adapt-V, a robust adaptation strategy for transferring pre-trained video diffusion models
The framework achieves extraordinary results:
- 14.8× faster inference compared to base models
- 230× lower training costs (only 10 H100 GPU days for Wan-2.1-14B)
- Supports high-resolution video generation with minimal computational overhead
Performance Benchmarks
In comprehensive testing across text-to-video and image-to-video generation tasks, DC-VideoGen demonstrated exceptional performance:
Text-to-Video Generation (720×1280 resolution):
- Reduced latency by 7.7×
- Improved VBench score from 83.73 to 84.83
- Outperformed leading models like OpenSora-2.0 and HunyuanVideo
Image-to-Video Generation (720×1280 resolution):
- 7.6× latency reduction
- Competitive VBench scores
- 5.8× faster than MAGI-1
- 8.3× faster than HunyuanVideo-I2V
Technical Approach
The researchers developed a novel 'chunk-causal' temporal modeling approach that addresses limitations in existing video autoencoders. By preserving causal information flow across chunks while enabling bidirectional flow within chunks, DC-VideoGen achieves superior reconstruction quality and generalization.
Learn More About DC-VideoGen
- Explore the project details on their GitHub repository: DC-VideoGen GitHub
- See demos of DC-VideoGen on their project page: DC-VideoGen Demos
- You can also review the technical paper on arXiv: DC-VideoGen Research Paper


