









Tencent Youtu-LLM-2B Powers Smart AI Agents
Tencent has introduced Youtu-LLM-2B, a lightweight language model containing 1.96 billion parameters that aims to harmonize computational efficiency with native agentic intelligence. Unlike many small models that rely on distillation from larger systems, this release was pre-trained from scratch using a gigantic 11 trillion tokens.
The model supports a large 128k context window, allowing it to maintain robust reasoning over long sequences, which is crucial for extended agent tasks. It utilizes a Dense Multi-Latent Attention (MLA) architecture, a design choice that facilitates robust long-context reasoning within a minimal memory footprint. This approach enables the model to systematically cultivate reasoning and planning capabilities rather than simply mimicking output behaviors.
Youtu-LLM's core features
- Two model variants: Youtu-LLM-2B-Base and Youtu-LLM-2B Instruct
- Dense Multi-Latent Attention
- 1.96B Parameters
- 130K+ Context Length
- 128K+ Vocabulary Size
- 32 Layers
Agentic benchmark performance
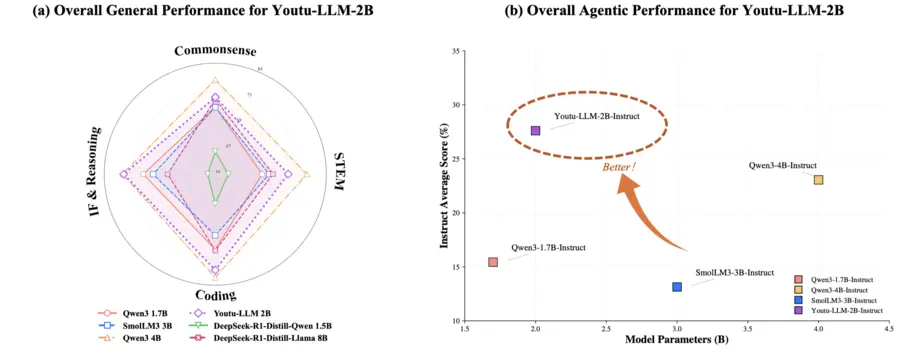
Performance evaluations indicate that Youtu-LLM sets a new standard for sub-2B parameter models. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing baselines. For instance, in the GAIA benchmark for deep research, the model achieved a score of 33.9%, outperforming the Qwen3-4B model which scored 25.5%.
It also demonstrated strong capability in code-related agent tasks, scoring 17.7% on SWE-Bench-Verified compared to 5.7% for the same competitor. The model also scored 95.9% on HumanEval, showcasing its proficiency in coding tasks. These results suggest that lightweight models can indeed possess strong intrinsic agentic capabilities when trained with the right methodology.
Pre-training methodology & further insights
The development team emphasizes that the model's strength comes from injecting agent-oriented signals early in the training process. The technical report states,
'Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities.'
The researchers argue that while existing methods often align output behavior, they fail to systematically cultivate underlying cognitive capabilities. By using a principled training paradigm that enhances native agentic capabilities, the team has provided evidence that agentic pre-training can unlock agent potential in lightweight LLMs. The paper further notes,
'We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy.'
Get full details on Youtu-LLM-2B
- Access the Youtu-LLM-2B on Hugging Face.
- For implementation details, visit their Github repository.
- Full details on their project paper here.


