









Qwen Launches Qwen3 TTS Multilingual Text-to-Speech AI
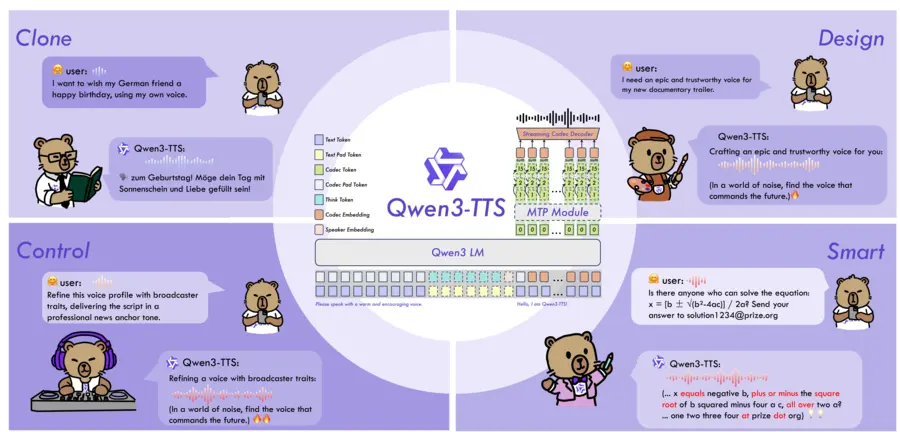
Qwen has introduced Qwen3 TTS, a versatile text-to-speech series trained on over 5 million hours of speech data across 10 different languages. The new AI technology delivers exceptional capabilities in voice cloning, generation, and control with unprecedented low-latency streaming performance.
Advanced Audio Capabilities
The Qwen3 TTS models showcase remarkable features that set them apart from existing text-to-speech technologies:
- Support for 3-second voice cloning
- Multilingual generation across 10 languages
- Ultra-low first-packet latency (97-101 ms)
- Natural language-based voice design and control
- Streaming text input and audio output
- Supports speaker-consistent multilingual generation
Model Family and How It Generates
The model family includes 5 models and a tokenizer, offering developers very flexible options for voice generation. Variants of the models include:
- Qwen3-TTS-12Hz-1.7B-CustomVoice
- Qwen3-TTS-12Hz-1.7B-VoiceDesign
- Qwen3-TTS-12Hz-1.7B-Base
- Qwen3-TTS-12Hz-0.6B-CustomVoice
- and Qwen3-TTS-12Hz-0.6B-Base
'We evaluate the model’s ability to clone unseen voices by measuring content consistency—specifically Word Error Rate (WER)—on the public Seed-TTS,' says one developer, noting their Zero-Shot Speech Generation. Another states, regarding the Multilingual Speech Generation 'To assess linguistic versatility, we examine both content intelligibility and speaker similarity in a zero-shot multilingual setting using the multilingual test set'.
Qwen 3 TTS Community and Accessibility
- Visit their GitHub repository
- Download the Qwen 3TTS models from Huggingface
- Read their Technical paper


